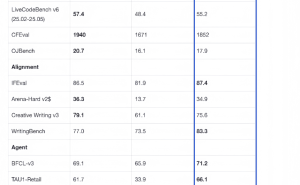
智源研究院近期推出了全新的原生多模态世界模型——Emu3,该模型在文本、图像及视频的理解与生成领域实现了显著突破。Emu3的创新之处在于,它仅需基于下一个token的预测,便能高效处理三种模态数据,无需依赖扩散模型或组合方法。

在图像生成方面,Emu3的性能超越了SD-1.5与SDXL模型;在视觉语言理解上,它则优于LlaVA-1.6;而在视频生成领域,Emu3的表现同样出色,超过了OpenSora 1.2。Emu3还具备强大的视觉tokenizer功能,能将视频和图像转换为离散token,与文本tokenizer输出的token共同送入模型处理。
研究表明,通过将复杂的多模态设计简化为token本身,Emu3在大规模训练和推理中展现出了巨大的潜力。目前,Emu3的关键技术和模型已经开源,项目页面也已正式上线。
对于研究人员而言,Emu3提供了一个统一的研究范式,值得深入探索。