近日,字节跳动旗下的Seed团队在开源领域迈出了重要一步,正式推出了Seed-OSS系列模型。这一系列模型专为长上下文处理、推理任务、智能体交互及通用场景设计,其上下文窗口长度达到了前所未有的512k,这一数字是业界常规标准的四倍,甚至超越了GPT-5的两倍,相当于能够一次性处理约1600页文本的信息量。
Seed-OSS系列模型不仅针对推理任务进行了深度优化,还创新性地引入了思维预算功能,允许用户根据实际需求灵活调整模型的推理成本。这一特性使得开发者能够在保证模型性能的同时,有效控制资源消耗,提升用户体验。
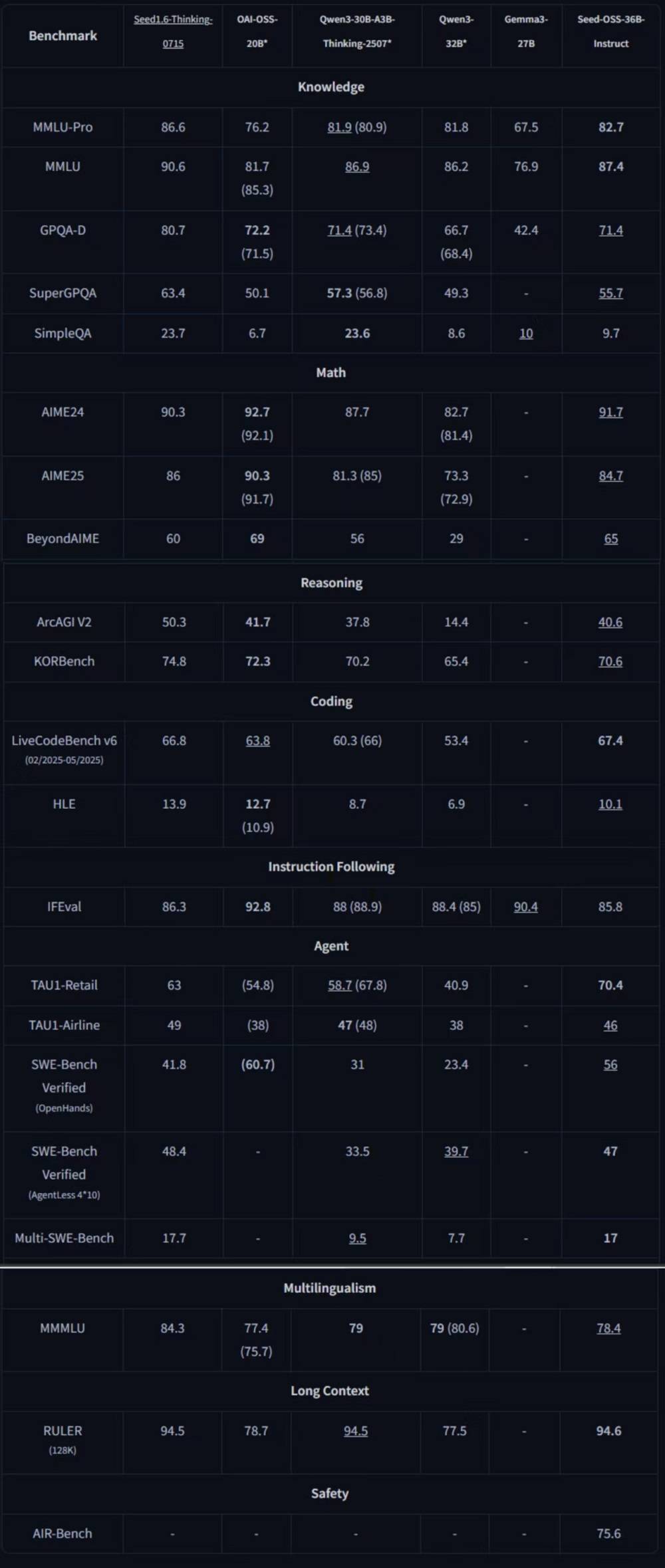
此次开源的Seed-OSS系列包括三个版本:基础模型Seed-OSS-36B-Base、无合成数据基础模型Seed-OSS-36B-Base-woSyn,以及经过指令微调的Seed-OSS-36B-Instruct。其中,指令微调后的Seed-OSS-36B-Instruct在多个领域的基准测试中表现出色,取得了同量级开源模型中的七项最佳性能(SOTA),整体实力超越了Qwen3-32B、Gemma3-27B、gpt-oss-20B等模型,与Qwen3-30B-A3B-Thinking-2507在多数领域不相上下。
值得注意的是,Seed团队在发布这一系列模型时,采取了极为“研究友好”的策略。考虑到合成指令数据在预训练中的潜在影响,团队特别发布了无合成数据基础模型,为科研工作者提供了更多样化的研究选项。Seed-OSS系列模型还支持4位和8位格式的量化处理,进一步降低了内存需求,提升了模型的应用灵活性。
在技术上,Seed-OSS系列模型采用了12万亿个token的预训练数据,并沿用了当前主流的因果语言模型架构。这一系列模型均为稠密模型,未采用MoE等复杂架构,而是结合了RoPE旋转位置编码、GQA注意力机制、RMSNorm归一化及SwiGLU激活函数等高效组件,以提升训练稳定性和推理性能。其512k的上下文窗口并非后续扩展而来,而是通过原生训练实现,能够一次性处理数十万字的内容。
思维预算功能的引入,使得开发者可以根据任务复杂度灵活调整模型推理成本。对于简单任务,模型思维链较短,分数波动不明显;而对于复杂任务,随着思维预算的增加,模型分数也会相应提升。若未设置思维预算,Seed-OSS将默认无思考长度限制;若指定预算,则建议优先考虑512的整数倍值,因为这些区间上的模型训练更为充分。
Seed-OSS系列模型的发布,在开源社区内引起了广泛关注。Hugging Face的华人工程师Tiezhen Wang评价称,这一系列模型非常适合进行消融研究,能够以较低成本探索不同组件对大模型性能的影响。网友们也纷纷表示,如此规模的基础模型在开源界实属罕见,长上下文能力对于实际应用具有重大意义。
近年来,开源已成为技术创新的重要推动力,连OpenAI等原本坚持闭源策略的厂商也开始逐步开源模型。字节跳动此次将核心语言模型贡献给社区,无疑为开源社区的后续研究提供了更多基础模型的选择,进一步推动了人工智能技术的开放与发展。

