人工智能领域迎来重要进展,Anthropic公司正式推出其最新大模型Claude Opus 4.7,这款模型被定位为当前最强大的通用型AI模型,在复杂任务处理、高清视觉理解以及长流程工作流稳定性方面实现了显著突破。
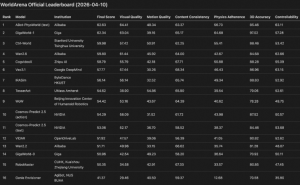
据官方介绍,Opus 4.7在视觉能力方面取得革命性进步。在特定基准测试中,其视觉理解得分从4.6版本的约50%跃升至接近满分水平,这种提升使AI在处理专业软件界面、复杂图表分析等任务时达到接近人类专家的水准。测试数据显示,该模型在ScreenSpot-Pro专业软件定位任务中,高分辨率场景下的准确率达到87.6%,相比前代提升近20个百分点。
在编程能力验证方面,新模型在SWE-bench Multilingual测试中取得80.5%的修复成功率,较前代提升2.7个百分点。更引人注目的是其在多模态编程任务中的表现,结合代码与UI截图处理前端bug的成功率从27.1%提升至34.5%。这种进步源于模型对屏幕元素的精准识别能力,使其能够理解视觉元素与代码逻辑之间的关联。
长任务处理能力是此次升级的核心亮点。在GraphWalks基准测试中,新模型在广度优先搜索任务中的表现从41.2%提升至58.6%,提升幅度达17.4个百分点。模拟自动售货机运营的Vending-Bench 2测试显示,相同时间窗口内新模型创造的收益较前代增长36%。这些数据表明,模型在持续数小时的复杂工作流中保持准确性的能力得到质的提升。
与主流竞品对比测试显示,Opus 4.7在知识工作场景中展现明显优势。在GDPval-AA评估中,新模型获得1753分,超越GPT-5.4的1674分和Gemini 3.1 Pro的1314分。在企业级推理基准OfficeQA Pro测试中,其80.6%的准确率分别是GPT-5.4和Gemini 3.1 Pro的1.6倍和1.9倍。在生物分子推理等垂直领域,新模型的表现更是达到前代的2.4倍。
对于普通用户,新模型带来三大直观改进:指令遵循能力显著增强,减少了对提示词的依赖;图像输入分辨率提升至2576像素长边,支持处理专业级图表;输出结果更接近可直接交付的成品,在文档美化、跨会话记忆等方面表现突出。这些改进使模型在材料润色、项目管理等场景中的实用性大幅提升。
技术团队特别强调,此次升级在安全性能方面保持审慎态度。新模型延续了Project Glasswing框架下的网络安全防护机制,内置自动检测系统可拦截高风险请求。安全评估显示,模型在诚实性指标和抵抗恶意注入方面表现优异,整体安全画像与前代保持相当水平。
开发团队提醒用户注意使用成本变化。由于采用新分词器和更高分辨率支持,相同输入的token消耗量可能增加1.0至1.35倍,高复杂度任务的输出token也会相应增长。不过官方维持了与前代相同的定价策略,未对基础服务费用进行调整。